Law of large numbers
In probability theory, the law of large numbers (LLN) is a theorem that describes the result of performing the same experiment a large number of times. According to the law, the average of the results obtained from a large number of trials should be close to the expected value, and will tend to become closer as more trials are performed.
For example, a single roll of a six-sided die produces one of the numbers 1, 2, 3, 4, 5, 6, each with equal probability. Therefore, the expected value of a single dice roll is
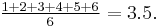
According to the law of large numbers, if a large number of six-sided dice are rolled, the average of their values (sometimes called the sample mean) is likely to be close to 3.5, with the accuracy increasing as more dice are rolled. This assumes that all possible dice roll outcomes are known and that Black Swan events such as a dice landing on edge or being struck by lightning mid-roll are not possible or ignored if they do occur.
It follows from the law of large numbers that the empirical probability of success in a series of Bernoulli trials will converge to the theoretical probability. For a Bernoulli random variable, the expected value is the theoretical probability of success, and the average of n such variables (assuming they are independent and identically distributed (i.i.d.)) is precisely the relative frequency.
For example, a fair coin toss is a Bernoulli trial. When a fair coin is flipped once, the theoretical probability that the outcome will be heads is equal to 1/2. Therefore, according to the law of large numbers, the proportion of heads in a "large" number of coin flips "should be" roughly 1/2. In particular, the proportion of heads after n flips will almost surely converge to 1/2 as n approaches infinity.
Though the proportion of heads (and tails) approaches 1/2, almost surely the absolute (nominal) difference in the number of heads and tails will become large as the number of flips becomes large. That is, the probability that the absolute difference is a small number, approaches zero as the number of flips becomes large. Also, almost surely the ratio of the absolute difference to the number of flips will approach zero. Intuitively, expected absolute difference grows, but at a slower rate than the number of flips, as the number of flips grows.
The LLN is important because it "guarantees" stable long-term results for random events. For example, while a casino may lose money in a single spin of the roulette wheel, its earnings will tend towards a predictable percentage over a large number of spins. Any winning streak by a player will eventually be overcome by the parameters of the game. It is important to remember that the LLN only applies (as the name indicates) when a large number of observations are considered. There is no principle that a small number of observations will converge to the expected value or that a streak of one value will immediately be "balanced" by the others. See the Gambler's fallacy.
Contents |
History
The Italian mathematician Gerolamo Cardano (1501–1576) stated without proof that the accuracies of empirical statistics tend to improve with the number of trials.[1] This was then formalized as a law of large numbers. A special form of the LLN (for a binary random variable) was first proved by Jacob Bernoulli.[2] It took him over 20 years to develop a sufficiently rigorous mathematical proof which was published in his Ars Conjectandi (The Art of Conjecturing) in 1713. He named this his "Golden Theorem" but it became generally known as "Bernoulli's Theorem". This should not be confused with the principle in physics with the same name, named after Jacob Bernoulli's nephew Daniel Bernoulli. In 1837, S.D. Poisson further described it under the name "la loi des grands nombres" ("The law of large numbers").[3][4] Thereafter, it was known under both names, but the "Law of large numbers" is most frequently used.
After Bernoulli and Poisson published their efforts, other mathematicians also contributed to refinement of the law, including Chebyshev,[5] Markov, Borel, Cantelli and Kolmogorov and Khinchin (who finally provided a complete proof of the LLN for arbitrary random variables). These further studies have given rise to two prominent forms of the LLN. One is called the "weak" law and the other the "strong" law. These forms do not describe different laws but instead refer to different ways of describing the mode of convergence of the cumulative sample means to the expected value, and the strong form implies the weak.
Forms
Two different versions of the Law of Large Numbers are described below; they are called the Strong Law of Large Numbers, and the Weak Law of Large Numbers. Both versions of the law state that – with virtual certainty – the sample average
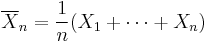
converges to the expected value
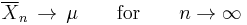
where X1, X2, ... is an infinite sequence of i.i.d. integrable random variables with expected value E(X1) = E(X2) = ...= µ. Integrability means that E(|X|1) = E(|X|2) = ... < ∞.
An assumption of finite variance Var(X1) = Var(X2) = ... = σ2 < ∞ is not necessary. Large or infinite variance will make the convergence slower, but the LLN holds anyway. This assumption is often used because it makes the proofs easier and shorter.
The difference between the strong and the weak version is concerned with the mode of convergence being asserted. For interpretation of these modes, see Convergence of random variables.
Weak law
The weak law of large numbers states that the sample average converges in probability towards the expected value[6][proof]
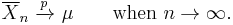
That is to say that for any positive number ε,
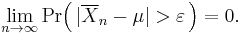
Interpreting this result, the weak law essentially states that for any nonzero margin specified, no matter how small, with a sufficiently large sample there will be a very high probability that the average of the observations will be close to the expected value, that is, within the margin.
Convergence in probability is also called weak convergence of random variables. This version is called the weak law because random variables may converge weakly (in probability) as above without converging strongly (almost surely) as below.
Strong law
The strong law of large numbers states that the sample average converges almost surely to the expected value[7]
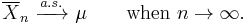
That is,
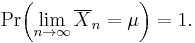
The proof is more complex than that of the weak law. This law justifies the intuitive interpretation of the expected value of a random variable as the "long-term average when sampling repeatedly".
Almost sure convergence is also called strong convergence of random variables. This version is called the strong law because random variables which converge strongly (almost surely) are guaranteed to converge weakly (in probability). The strong law implies the weak law.
The strong law of large numbers can itself be seen as a special case of the pointwise ergodic theorem.
Moreover, if the summands are independent but not identically distributed, then
![\overline{X}_n - \operatorname{E}\big[\overline{X}_n\big]\ \xrightarrow{a.s.}\ 0](/2012-wikipedia_en_all_nopic_01_2012/I/7c97cb40676d14659a0eb21f798acff0.png)
provided that each Xk has a finite second moment and
![\sum_{k=1}^{\infty} \frac{1}{k^2} \operatorname{Var}[X_k] < \infty.](/2012-wikipedia_en_all_nopic_01_2012/I/63c48d6a32fad561ece28d5ed18b2a64.png)
This statement is known as Kolmogorov's strong law, see e.g. Sen & Singer (1993, Theorem 2.3.10).
Differences between the weak law and the strong law
The weak law states that for a specified large n, the average 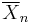 is likely to be near μ. Thus, it leaves open the possibility that
is likely to be near μ. Thus, it leaves open the possibility that 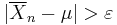 happens an infinite number of times, although at infrequent intervals.
happens an infinite number of times, although at infrequent intervals.
The strong law shows that this almost surely will not occur. In particular, it implies that with probability 1, we have that for any ε > 0 the inequality 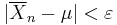 holds for all large enough n.[8]
holds for all large enough n.[8]
Uniform law of large numbers
Suppose f(x,θ) is some function defined for θ ∈ Θ, and continuous in θ. Then for any fixed θ, the sequence {f(X1,θ), f(X2,θ), …} will be a sequence of independent and identically distributed random variables, such that the sample mean of this sequence converges in probability to E[f(X,θ)]. This is the pointwise (in θ) convergence.
The uniform law of large numbers states the conditions under which the convergence happens uniformly in θ. If [9][10]
- Θ is compact,
- f(x,θ) is continuous at each θ ∈ Θ for almost all x’s, and measurable function of x at each θ.
- there exists a dominating function d(x) such that E[d(X)] < ∞, and
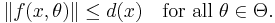
Then E[f(X,θ)] is continuous in θ, and
![\sup_{\theta\in\Theta} \left\| \frac1n\sum_{i=1}^n f(X_i,\theta) - \operatorname{E}[f(X,\theta)] \right\| \xrightarrow{\mathrm{a.s.}} \ 0.](/2012-wikipedia_en_all_nopic_01_2012/I/95c15106ee7228453f56f4dabd1eedad.png)
Borel's law of large numbers
Borel's law of large numbers, named after Émile Borel, states that if an experiment is repeated a large number of times, independently under identical conditions, then the proportion of times that any specified event occurs approximately equals the probability of the event's occurrence on any particular trial; the larger the number of repetitions, the better the approximation tends to be. More precisely, if E denotes the event in question, p its probability of occurrence, and Nn(E) the number of times E occurs in the first n trials, then with probability one,
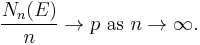
This theorem makes rigorous the intuitive notion of probability as the long-run relative frequency of an event's occurrence. It is a special case of any of several more general laws of large numbers in probability theory.
Proof
Given X1, X2, ... an infinite sequence of i.i.d. random variables with finite expected value E(X1) = E(X2) = ... = µ < ∞, we are interested in the convergence of the sample average
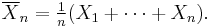
The weak law of large numbers states:
Theorem: 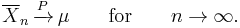
Proof using Chebyshev's inequality
This proof uses the assumption of finite variance 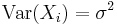 (for all
(for all  ). The independence of the random variables implies no correlation between them, and we have that
). The independence of the random variables implies no correlation between them, and we have that
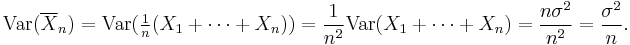
The common mean μ of the sequence is the mean of the sample average:
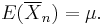
Using Chebyshev's inequality on results in
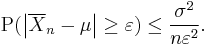
This may be used to obtain the following:
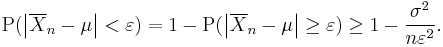
As n approaches infinity, the expression approaches 1. And by definition of convergence in probability (see Convergence of random variables), we have obtained
Proof using convergence of characteristic functions
By Taylor's theorem for complex functions, the characteristic function of any random variable, X, with finite mean μ, can be written as
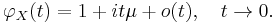
All X1, X2, ... have the same characteristic function, so we will simply denote this φX.
Among the basic properties of characteristic functions there are
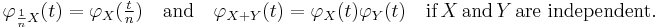
These rules can be used to calculate the characteristic function of 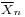 in terms of φX:
in terms of φX:
![\varphi_{\overline{X}_n}(t)= \left[\varphi_X\left({t \over n}\right)\right]^n = \left[1 %2B i\mu{t \over n} %2B o\left({t \over n}\right)\right]^n \, \rightarrow \, e^{it\mu}, \quad \textrm{as} \quad n \rightarrow \infty.](/2012-wikipedia_en_all_nopic_01_2012/I/c4232cec4155489233c29696d807546a.png)
The limit eitμ is the characteristic function of the constant random variable μ, and hence by the Lévy continuity theorem, converges in distribution to μ:
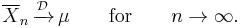
μ is a constant, which implies that convergence in distribution to μ and convergence in probability to μ are equivalent. (See Convergence of random variables) This implies that
This proof states, in fact, that the sample mean converges in probability to the derivative of the characteristic function at the origin, as long as this exists.
See also
Notes
- ^ Mlodinow, L. The Drunkard's Walk. New York: Random House, 2008. p. 50.
- ^ Jakob Bernoulli, Ars Conjectandi: Usum & Applicationem Praecedentis Doctrinae in Civilibus, Moralibus & Oeconomicis, 1713, Chapter 4, (Translated into English by Oscar Sheynin)
- ^ Poisson names the "law of large numbers" (la loi des grands nombres) in: S.D. Poisson, Probabilité des jugements en matière criminelle et en matière civile, précédées des règles générales du calcul des probabilitiés (Paris, France: Bachelier, 1837), page 7. He attempts a two-part proof of the law on pages 139-143 and pages 277 ff.
- ^ Hacking, Ian. (1983) "19th-century Cracks in the Concept of Determinism", Journal of the History of Ideas, 44 (3), 455-475 JSTOR 2709176
- ^ P. Tchebichef (1846) "Démonstration élémentaire d'une proposition générale de la théorie des probabilités," Journal für die reine und angewandte Mathematik, vol. 33, pages 259-267.
- ^ Loève 1977, Chapter 1.4, page 14
- ^ Loève 1977, Chapter 17.3, page 251
- ^ Ross (2009)
- ^ Newey & McFadden 1994, Lemma 2.4
- ^ Robert I. Jennrich, Asymptotic Properties of Non-Linear Least Squares Estimators, Ann. Math. Statist. Volume 40, Number 2 (1969), 633-643.
References
- Grimmett, G. R. and Stirzaker, D. R. (1992). Probability and Random Processes, 2nd Edition. Clarendon Press, Oxford. ISBN 0-19-853665-8.
- Richard Durrett (1995). Probability: Theory and Examples, 2nd Edition. Duxbury Press.
- Martin Jacobsen (1992). Videregående Sandsynlighedsregning (Advanced Probability Theory) 3rd Edition. HCØ-tryk, Copenhagen. ISBN 87-91180-71-6.
- Loève, Michel (1977). Probability theory 1 (4th ed.). Springer Verlag.
- Newey, Whitney K.; McFadden, Daniel (1994). Large sample estimation and hypothesis testing. Handbook of econometrics, vol.IV, Ch.36. Elsevier Science. pp. 2111–2245.
- Ross, Sheldon (2009). A first course in probability (8th ed.). Prentice Hall press. ISBN 978-0136033134.
- Sen, P. K; Singer, J. M. (1993). Large sample methods in statistics. Chapman & Hall, Inc.
External links
- Weisstein, Eric W., "Weak Law of Large Numbers" from MathWorld.
- Weisstein, Eric W., "Strong Law of Large Numbers" from MathWorld.
- Animations for the Law of Large Numbers by Yihui Xie using the R package animation